Data entry tools for academia
Table of Contents
In academia, technology choices often follow the path of least resistance. When a project gets greenlit, the principal investigator typically reaches for whatever they know best: Google Forms for surveys, Sheets for curation, and Drive for storage. If data needs to be collected offline, Microsoft Access becomes the default choice. While these tools work initially, they rarely scale gracefully.
The challenge of picking the right tool in the long term is a mix of technical factor and resource constraints. Academic environments often lack dedicated IT support, budgets are tight, and the primary users are researchers, not developers. Conversely, compliance and audit requirements overlap with enterprise requirements without the enterprise budget. This creates a unique set of constraints that enterprise solutions don't address well especially in terms of privacy.
Criteria for ideal data entry tools
Through our experience across multiple projects, we've identified the essential criteria for academic data entry tools. These criteria are based on our experience and the needs of our research projects.
- Scalability: Adding users shouldn't create exponential work
- Privacy: Data must remain within the research team's control
- Authentication: Integration with institutional credentials
- Compliance: Built-in audit trails and version control
- Integration: Easy export to a standard database format or integration with a database
- Mobile: Native mobile/tablet apps for data entry
- Setup complexity: IT skills required for setup. In an ideal world this factor would be inconsequential however it is a barrier to entry for many academic projects where IT support is not available.
- Extendability: Non-technical users can customize forms and workflows
- Availability: Reasonable for academic budgets or availability in academic institutions
- Offline capability: Works without access to internet.
- File attachments: Support for images, documents, media or other files.
Evaluating the landscape
Here is a list of tools that I've used in the past and how they compare to our criteria.
- Google Forms: Has the lowest friction if your organization uses Google Workspace. If PII is not a factor, it's a good option for simple surveys and basic data collection.
- Microsoft Access: Although discontinued and unsupported by Microsoft, it is still possibly the best candidate for data collection in offline or air-gapped environments. Researchers are typically familiar with setting it up however, it doesn't scale well for multi-user environments, especially when forms need to be updated or backed up frequently.
- KoboToolbox: A set of data collection tools that came out of Harvard. It is the most polished of all existing options. While they offer a generous free tier, it can become expensive quickly if you need to use attachments. Everything works in a browser, and data can be recorded offline and synced in the background later. They also provide a robust API for integration with other tools, as well as the source code for self-hosting.
- Directus: An open-source data platform that provides a database GUI with fine-grained permissions, audit trails, and form building capabilities. Discussed in more detail below.
- Epicollect: A mobile and web-based data collection platform developed by the University of Oxford, designed for field research with strong offline capabilities. They also have a robust API for integration with other tools and authentication with Google.
- REDCap: Developed by Vanderbilt University, REDCap is a secure web application for building and managing online surveys and databases, widely used in academic research. It is the gold standard for academic research, especially when it comes to HIPAA compliance. Their license terms require all IT support to come from within your own organization, which can be a concern for some research projects.
| Tool | Scale | Setup | Priv | Auth | Ext | Integ | Comp | Avail | Attach | Offline | Mobile |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Google Forms | 3 | 3 | 1 | 3 | 3 | 1 | 1 | 2 | 3 | 1 | 2 |
| Microsoft Access | 1 | 2 | 3 | 3 | 3 | 2 | 1 | 1 | 1 | 3 | 1 |
| KoboToolbox | 3 | 3 | 2 | 1 | 3 | 3 | 2 | 2 | 3 | 3 | 2 |
| Directus | 3 | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 1 | 3 |
| Epicollect | 3 | 3 | 2 | 3 | 3 | 3 | 2 | 2 | 3 | 3 | 3 |
| REDCap | 3 | 2 | 3 | 3 | 2 | 3 | 3 | 3 | 3 | 3 | 3 |
Rating Scale: 1 = Not suitable, 2 = Suitable in some circumstances, 3 = Suitable
The Verdict: REDCap emerges as the gold standard, but it's often unavailable outside established academic institutions, particularly outside the US. This availability gap led us to explore alternatives. If offline data collection is not a requirement then the next best option is Directus.
The Search for a Database GUI
My ideal solution would function like an Object Relational Mapping (ORM) with a graphical interface—something that would let non-technical users create forms and manage data without writing code. Something like Django admin but with the ability to extend it without code.
ORM is a design pattern that provides a way to map database tables to objects in a programming language. More crucially, it abstracts away the database management component and allows for programmers with limited database experience to create, manage and query databases without having to write SQL. A secondary benefit being that the database schema can be versioned and managed through code, making it easier to track changes through git. It is my preferred way of managing databases.
This led me down the "no-code" builder path, where I discovered tools like Retool and similar platforms. These builders promised everything but delivered frustration. They required substantial JavaScript knowledge for anything beyond basic functionality and manipulated databases in ways that made external data entry problematic. These tools were built for developers who wanted to prototype quickly, not for researchers who needed sustainable data management.
Shifting my search terms from "no-code builders" to "database management GUIs" led me to database CI/CD tools like Bytebase. These were very promising and allowed for robust data governance and compliance with the administrator having the ability to enforce audit trails and version control. However, the tool was designed for database administrators and some of the security features were behind a paywall.
Ultimately, after tweaking the search terms some more, I found Directus, a tool that positioned itself as a headless Content Management System (CMS) but proved to be exactly what we needed for research data management.
Directus as a Database Management Tool
Directus introduces itself as a tool to "Create, manage, and scale headless content," but beneath that marketing speak lies a powerful data management platform. Out of the box, it provides:
- GUI for direct database manipulation
- Form creation and management
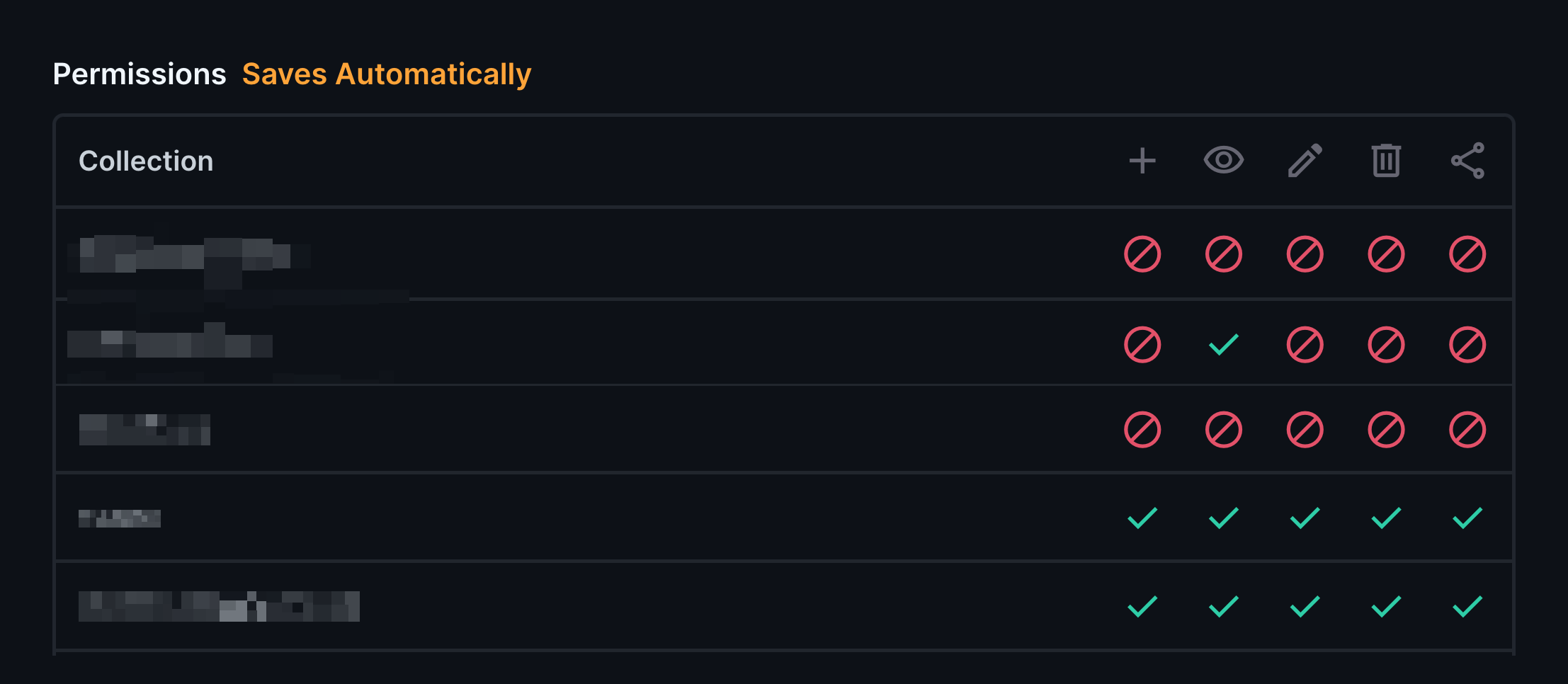
- Authentication and granular permissions
- Audit trails for all actions
- File attachment support
- Multi-language support
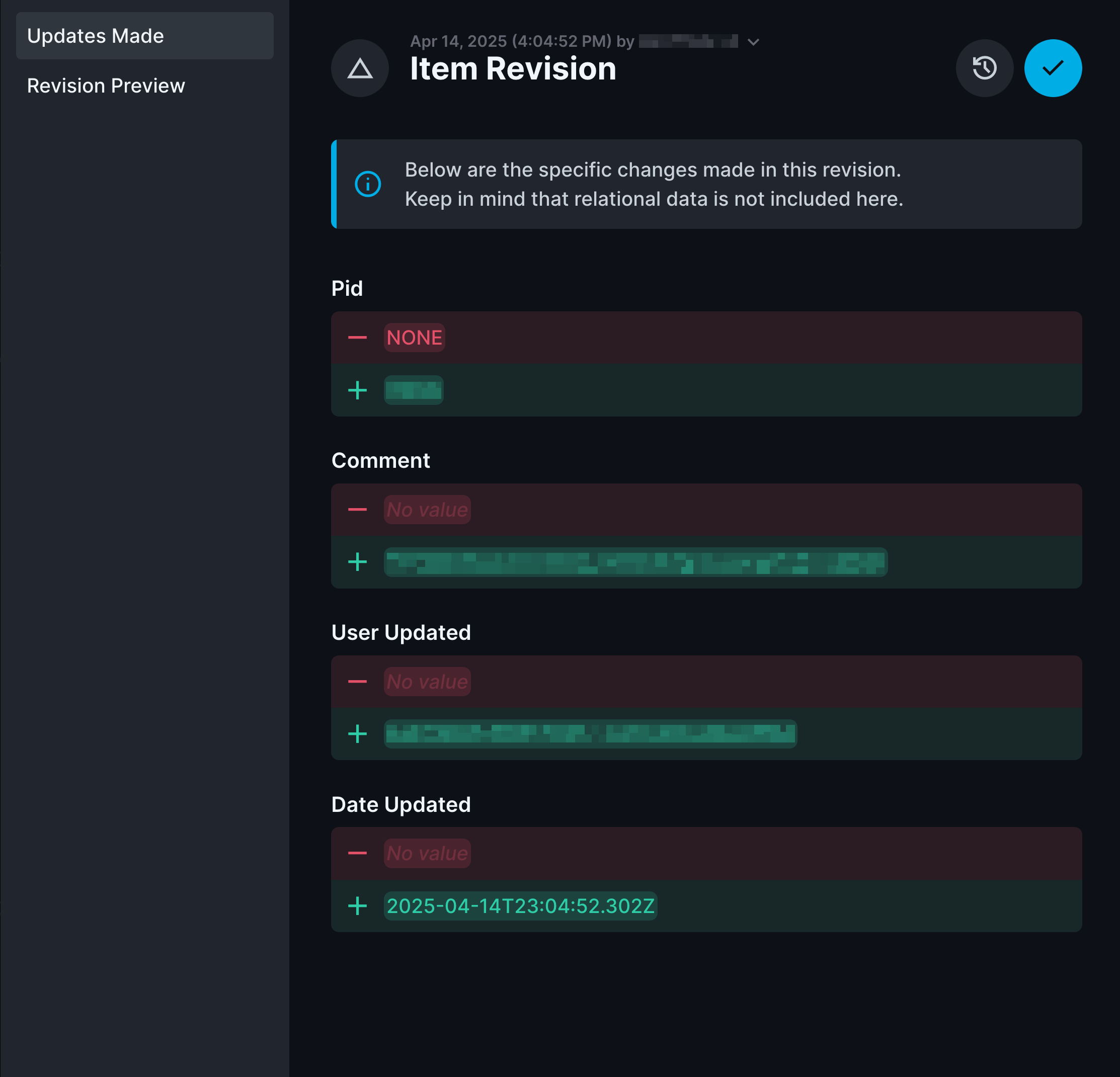
These features address every pain point we'd experienced with previous tools. The data model GUI allows non-technical users to create complex relationships between tables, while the built-in audit system tracks every change with timestamp and user attribution. Each data model also generates forms for data entry that can be customized to the needs of the project.
Real-World Implementation: THLHP
The Tsimane Health and Life History Project provided the perfect test case for our new approach. This longitudinal biomedical study, running since 2001, focuses on understanding healthy aging among the Tsimane indigenous group in Bolivia's lowlands. The project has collected extensive demographic, genetic, biochemical, and medical imaging data across over two decades.

BBC Documentary: The Tsimane Tribe
Learn about the Tsimane indigenous group and THLHP studying their health and aging patterns in Bolivia's lowlands.
Multi-Language Challenge
Our data collection happens in Tsimane and Spanish in the field, while analysis occurs in English. Directus's translation capabilities work at both the data model level and content level, allowing us to maintain consistency across languages without data duplication.
File Management Revolution
Previously, we organized binary files using directory structures. This system worked with small teams but became unwieldy as the project grew. Different users wanted different organizational schemes, and finding specific files became a time-consuming treasure hunt.
Directus transformed our approach by storing file metadata in the database while maintaining the files themselves in organized storage. Each uploaded file gets a unique identifier, preserving the original filename in the database for easy searching and organization. This also enabled us to write database queries to find specific files based on information in other related database tables.
Directus as a LIMS
Managing biosamples requires implementing FAIR principles (Findable, Accessible, Interoperable, Reusable),something nearly impossible with traditional file systems. Purpose-built Laboratory Information Management Systems (LIMS) exist but are expensive or require dedicated IT support.
Directus's comprehensive audit trail, version tracking, and soft delete capabilities make it an effective LIMS alternative. Every sample's journey through our system is documented, traceable, and recoverable.
The Path Forward
For most academic projects, I'd recommend this decision tree:
- If you have institutional access: REDCap remains the gold standard
- If you can self-host: Directus provides enterprise-level capabilities with academic-friendly complexity
- If you need minimal infrastructure: Consider Pocketbase, which offers a subset of Directus features in a single binary
- If you're just starting: Begin with your current tools, but plan for migration before you hit scalability walls
The key insight from our experience is that data entry tools aren't just about collecting information but about creating sustainable systems that support research over time. The tool you choose today will either enable or constrain your research for years to come especially in downstream analysis.